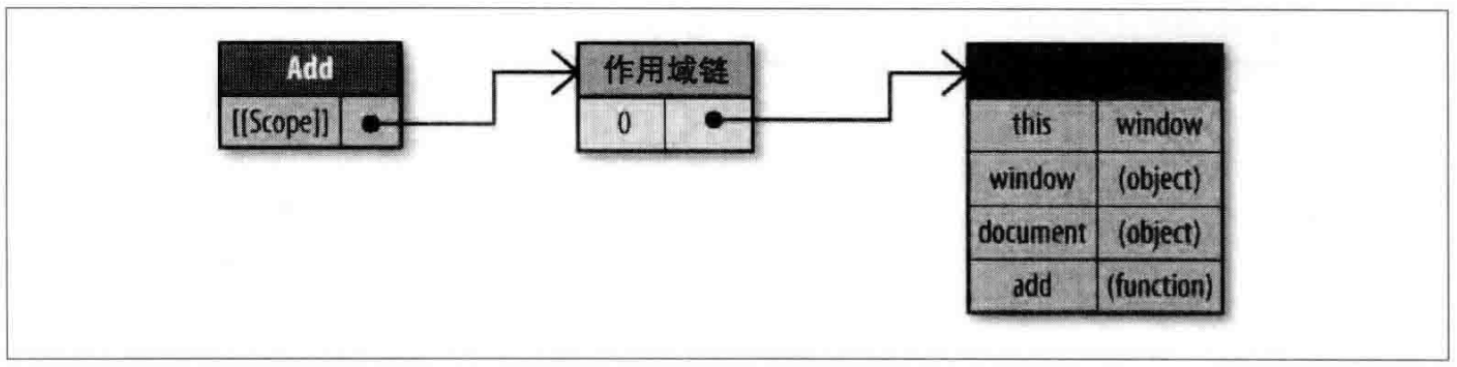
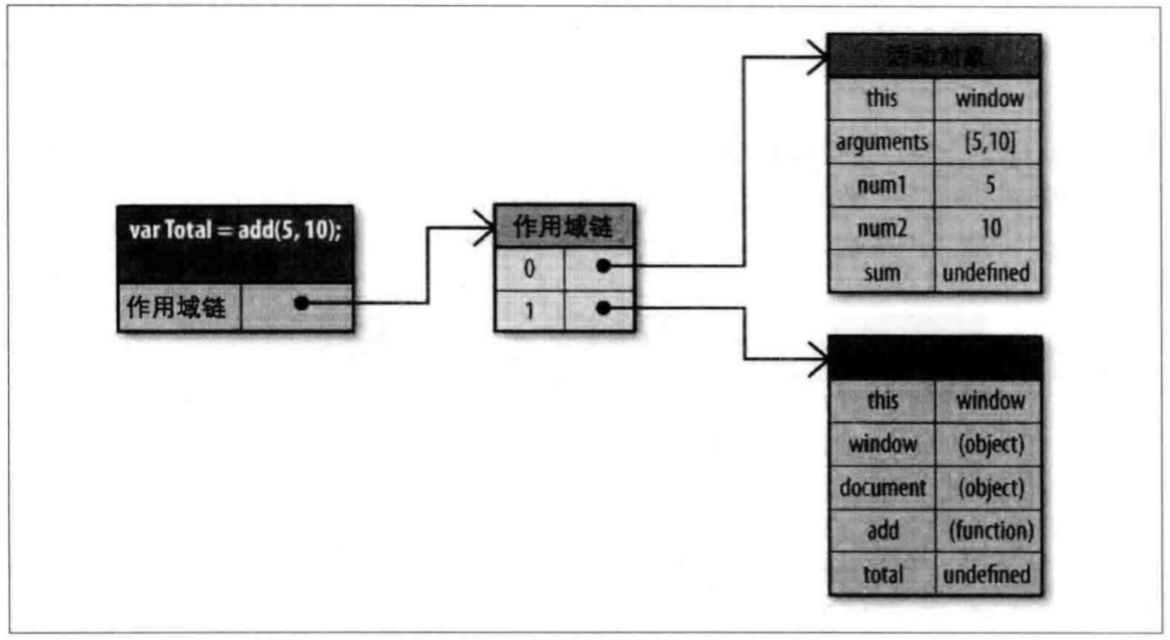
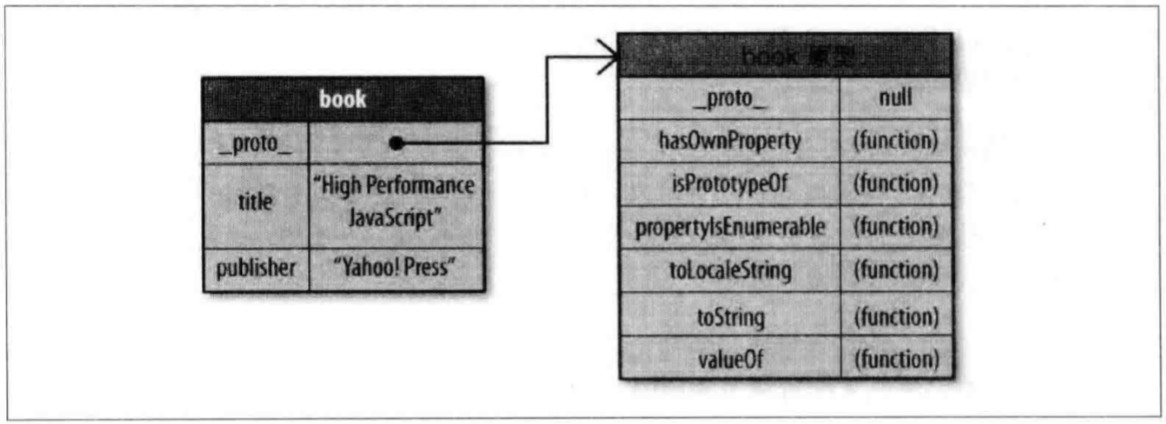
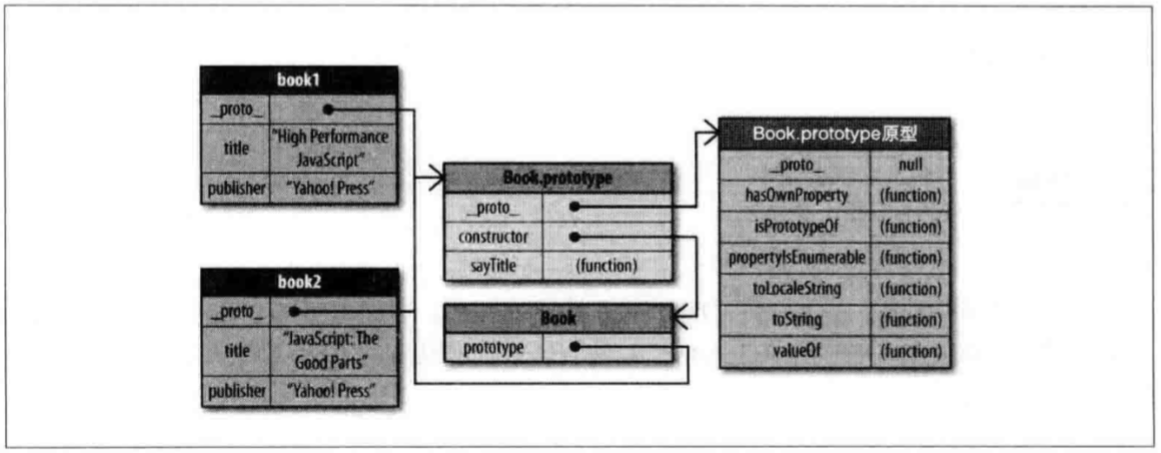
上一篇讲了一下创建对象的三种模式,本篇就来讲一下继承。
继承
这里说的继承是指构造函数的继承。一般继承是在设计中把一些不同类型的对象的共同点抽象出来,或者是在原有的构造函数中继承出新的构造函数,减少代码冗余。
继承可以使子类拥有父类的属性跟方法,而且不会出现重复的代码。
最简单的方式就是在子类的构造函数中创建一个父类的实例对象,再把子类自有的属性跟对象添加到这个实例对象上,在返回出来。
代码1 项目中怪兽子类继承飞机父类1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21function Plane (option, context) {
this.opts = option;
this.context = context;
}
Plane.prototype.drawing = function () {
// 画布上渲染图片
}
Plane.prototype.move = function () {
// 飞机每帧移动
}
// 其他方法省略
function Enemy (option, context) {
this.prototype = new Plane(option, context);
}
Enemy.prototype.drawing = function () {
// 重写方法
}
这种方案虽然能实现子类对父类的继承,但是出现了以下的几个问题:子类的实例对象的constructor指向了父类的构造函数,原因是子类构造函数中先创建了一个父类的实例对象,这个对象的constructor肯定指向父类的构造函数。
因此,在上面的代码基础上,还需要把constructor指向自身,可以解决这个问题了。
代码2 项目中怪兽子类继承的优化1
2
3
4
5
6
7
8function Enemy (option, context) {
this.prototype = new Plane(option, context);
this.protptype.constructor = Enemy;
}
Enemy.prototype.drawing = function () {
// 重写方法
}
但是,这里可以看到,有些方法可能会需要重写,这个问题不大,但是会有属性覆盖父类属性的问题,所以这点也是需要优化的,减少创建出来的对象的冗余。
这里要补充一个,还可以直接通过call()绑定父类构造函数进行继承,但是写在原型上的方法都没法用。但是也是我们参考的一个点
代码3 项目中怪兽子类绑定飞机父类构造函数1
2
3
4function Enemy (option, context) {
Plane.call(this, option, context);
// 其他省略
}
以上的问题点其实都是在如何可以准确的继承父类的方法,减少属性覆盖,又保证子类constructor指向子类的构造函数。这里我用到了这个项目前学习到的继承方案,包括以下的函数
代码4 inheritPrototype()方法1
2
3
4
5
6
7
8
9
10
11
12
13/**
* @description 继承父类原型对象的函数
* @param {Object} subType 子类对象
* @param {Object} subType 父类对象
*/
var inheritPrototype = function (subType, superType) {
// 把父类对象的原型对象赋值给proto
var protoType = Object.create(superType.prototype);
// proto的constructor指向子类对象,进行重置
protoType.constructor = subType;
// 把子类的原型指向原型
subType.prototype = protoType;
}
这个方案利用了构造函数继承跟上面的inheritPrototype()方法。前者继承了父类的属性,后者函数继承了父类原型中的所有方法。最终的效果如下:
代码5 项目中的继承设计1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19function Plane (option,context) {
this.opts = option;
this.context = context;
}
Plane.prototype.drawing = function () {
// 画布上渲染图片
}
function Enemy(options,context) {
// 继承父类Plane的属性
Plane.call(this, options, context);
}
// 继承父类Plane的原型
inheritPrototype(Enemy, Plane);
Enemy.prototype.drawing = function () {
// 重写方法
}
下一篇介绍项目中对象的设计。